Points to remember while processing streaming timeseries data in order using Kafka and Spark
Saturday / 26 January 2019 / SparkI skipped writing this post thinking it would be basic. But after getting same doubts from my colleagues and remembering the mistakes I did in past, think this post will be helpful for people to understand how to process streaming data without messing up the order in which they are produced.
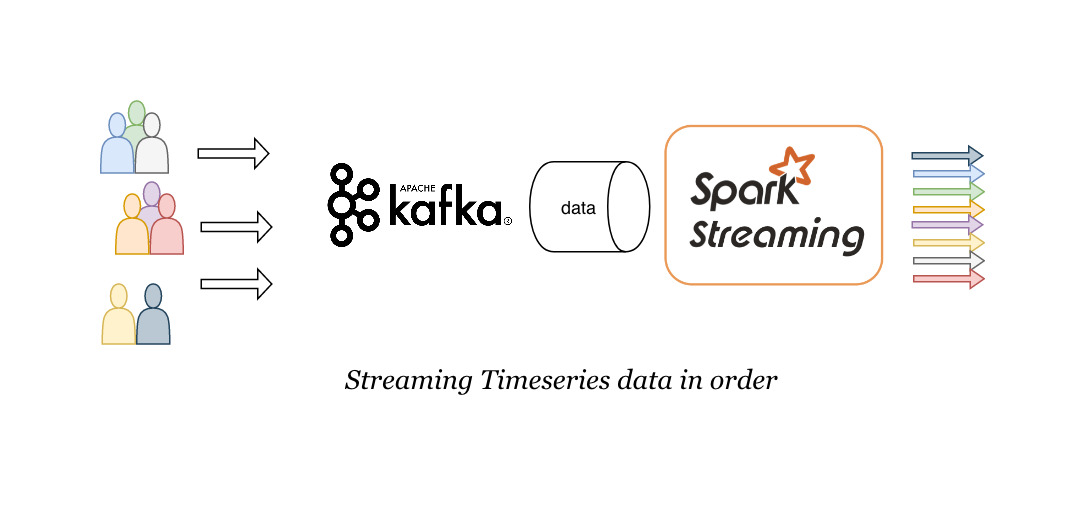
In one of my previous posts, I had explained about using Kafka as data source for Spark batch jobs. In this post, I intend to highlight few points for processing streaming data in sorted order which is very important for many business usecases.
This post only focuses on handling data that are already being produced in order by the datasource. Below points are applicable for processing events in order in which they are produced. There is a different programming model (Structured streaming) in Spark if your data itself is produced out of order by the datasource.
About sample application
For explaining the cases, I have built a sample application & pushed the Source codes in this Git repo with Readme of how to execute. We shall consider processing events like pageview/click triggered from browser for this sample application. Below is a simple schema in Avro for such data.
1. Use right partition key to distribute your data
Kafka stores the logs of each partition of a topic in separate logs directory. So if your application requires data to be consumed in same order as its being produced, choosing right partition key is important.
In the sample application, we can choose user_id as our partition key since we need events to be stored in order with the context of each user. By default, Kafka uses hash of the key & no. of partitions available in the topic to decide which partition to place it. You can change this by using a custom partitioner or map each event to a specific partition while pushing to topic. The default behaviour is good for most of the applications.
For a topic of 4 partitions, each partition has logs for a subset of keys in same order as they are pushed. Though multiple datasources can write to the topic at different intervals, two sources shouldn’t produce data for single key as the timestamps & write intervals may differ.
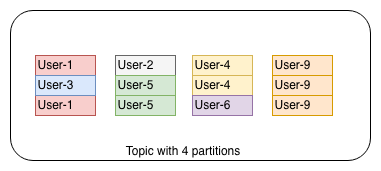
2. Scale partitions depending on your executors
More partitions means higher throughput in Kafka. There is a good post about understanding what is the recommended partitions for a topic. In streaming context, Spark doesn’t create consumer groups based on the executors available for the job. But rather Spark’s ConsumerCoordinator creates a consumer-group for each partition of the topic and is distributed as tasks to all executors with offsets split for each batch.
In below screenshot you can see for a topic of 900 partitions (max recommended for my setup), Spark creates equal number of tasks that is being processed by all available executors parallelly. The high number of partitions increases the processing time for each batch & thus introduces latency to streaming pipeline.
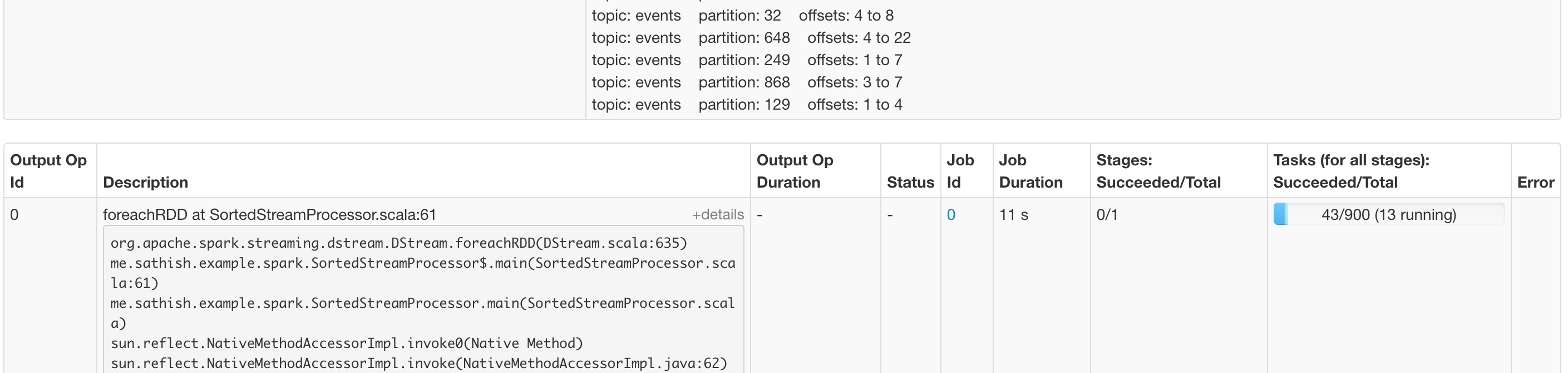
In this sample application, the time taken to process 12K records in a batch of 8 partitions is lesser when compared to 900 partitions of same volume of data.
Kafka supports changing number of partitions for a topic after it is created. But be aware that you can’t scale down the partitions once you scaled up. The topic has to be deleted & created newly if you have to scale down.
3. Don’t use functions that shuffles/repartitions the data.
Spark repartitions the Dataframe / Rdd when you apply sort by column or sortBy. This default behaviour changes the order of the messages when they are reshuffled to different partitions.
You can use using repartitionAndSortWithinPartitions that supports use of custom partitioner which can be used while sorting data. This blog post explains in detail about using the technique for mapping data to partition in sorted order.
4. Throttle the volume of messages & setup right batch interval
By default, Spark fetches all available messages for each partition of a topic while executing each batch. This behaviour will make your spark job to fail when there is a burst of data in single batch that exceeds executor memory. For Streaming applications that runs in production, its recommended to set the backpressure & maxRatePerPartition for throttling the data volume of each batch.
$ spark-submit --conf spark.streaming.backpressure.enabled=true --conf spark.streaming.kafka.maxRatePerPartition=5000 --executor-cores 4 --num-executors 4 --class me.sathish.example.spark.SortedStreamProcessor --master yarn kafka_stream_processing_sorted_order_2.11-1.0.jar config.ymlSetup the batch interval of the application as average process-time first few batches to avoid queuing of future batches. Though queuing don’t have direct impact on the running application, the latency of the pipeline builds up of not handled properly.
5. Save offsets of all partitions for processed data & restart from saved offsets
Streaming application run for long and the business logic keeps changing over period. So in actual production scenario, apart from job failures we may have to stop current application & schedule a new version with updated logic. In order to ensure there is no data loss on such cases, make sure to shutdown the application gracefully & restart from saved offsets. Spark supports saving offsets of messages in three ways.
When compared to checkpointing & saving offsets in kafka itself, I prefer the approach of saving offsets to external source as its not affected by code changes and also has the flexibility of modifying offsets in case of mishaps.
I hope these points were helpful in understanding the concepts for processing messages in order using Spark.