It’s time to ditch Apache Spark and love Dask
Blog / SparkAfter a long time, I couldn’t stop myself from writing this blog. This is not about comparing two of these frameworks but if you are interested in that, Dask is humble enough to include that in their official documentation as well. Am just sharing personal opinion from building applications using both of these frameworks.
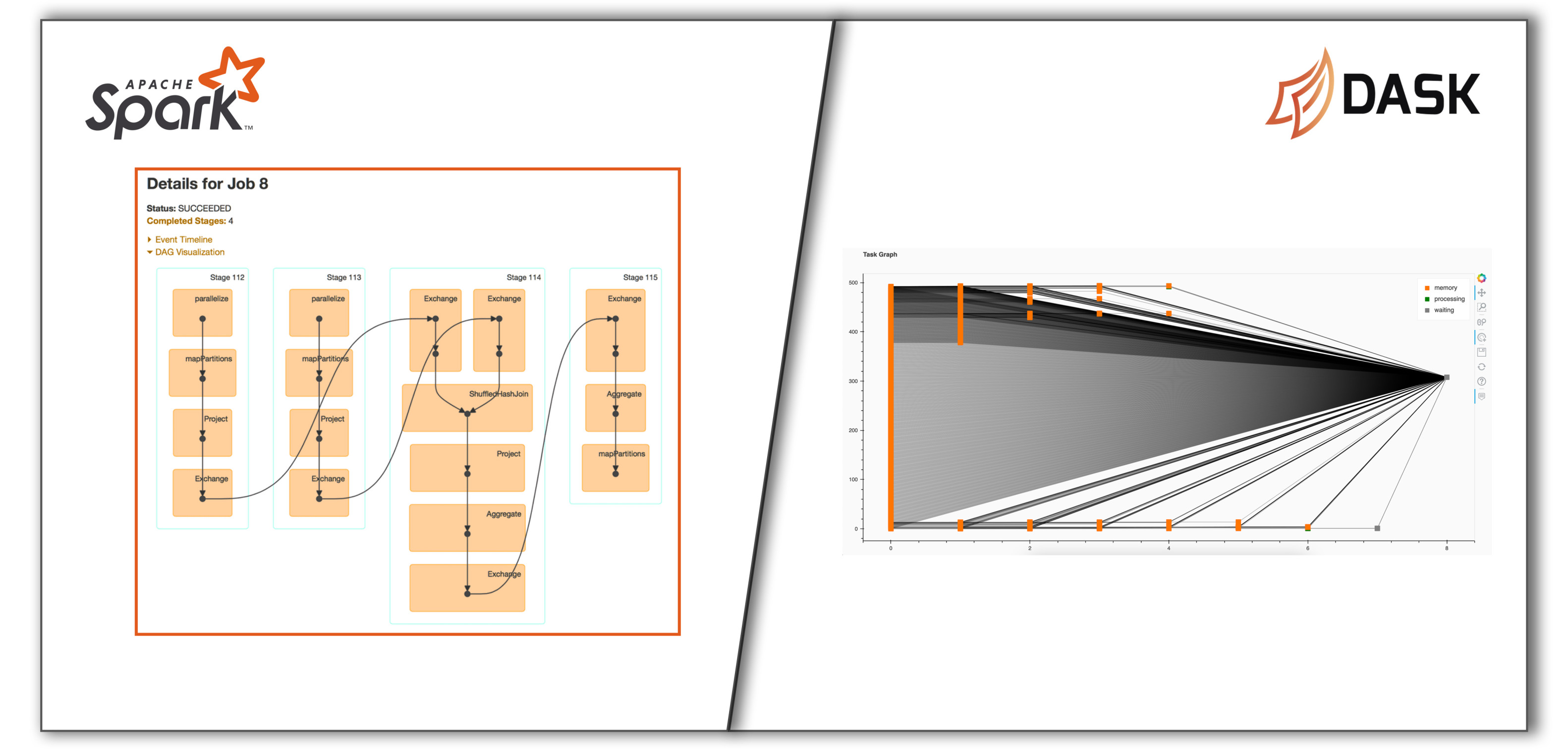
Spark is great, but…
At Quartic.ai, we have built multiple jobs using Apache Spark that does ingress, ETL, score models, etc for different kinds of data which are of both streaming & batch nature. Spark’s rich set of APIs would make your job easy if you have everything as dataframes & RDDs spread across multiple nodes in cluster. But the problem lies in building the required dataframes just so we can make use of the APIs provided by Spark. This is the time to call
Points to remember while processing streaming timeseries data in order using Kafka and Spark
Blog / SparkI skipped writing this post thinking it would be basic. But after getting same doubts from my colleagues and remembering the mistakes I did in past, think this post will be helpful for people to understand how to process streaming data without messing up the order in which they are produced.
Tips & tools I use for faster development as a Full Stack Developer
Blog / PersonalI had been so held up with work all these days & didn’t realize that I left this place awfully quiet which is embarrassing. So am writing this post as its easy to write about what I use everyday.
Batch processing of multi-partitioned Kafka topics using Spark with example
Blog / ScalaThere are multiple usecases where we can think of using Kafka alongside Spark for streaming realtime ETL processing involved in projects like tracking web activities, monitoring servers, detecting anomalies in Engine parts and so on. The architecture involves the source producing data which is sent to a Kafka topic & the consumer processes the data for every predefined batch interval.
Import data from CSV files to HBase using Spark
Blog / JavaSpark has multiple tutorials, examples & Stackoverflow solutions. But most of them are in Scala. If you want to develop something in Java, you are left with what is available in the Spark’s examples package & few blog posts using older APIs for reference. This post aims to be an additional reference for the new Spark API(2.1.X) focusing on importing data from CSV files into HBase table.
Pondicherry to Goa - Bike ride
Blog / PersonalTitle sounds cool right? But no, I actually didn’t make the whole trip on my bike (Fortunately). And this wasn’t one of those leisure trips where I plan my routes, select places to visit & make arrangements for my stay. This was more of a relocation . Yes, I was moving to Goa for my job.